ШІ-моделі «зламали» смартконтракти на $550,1 млн

Компанія Anthropic застосувала ШІ-моделі для пошуку вразливостей у смартконтрактах і виявила вектори для атак на загальну суму $550,1 млн.
Дослідники MATS і Anthropic Fellows створили новий бенчмарк Smart CONtracts Exploitation benchmark (SCONE-bench) — він охоплює 405 контрактів, зламаних у період з 2020 по 2025 роки.
Експерти оцінили 10 моделей, які сукупно згенерували робочі експлойти для 207 протоколів (51,11%) і змогли «викрасти» кошти на $550,1 млн.
Окремо для контрактів, зламаних після березня 2025 року (останньої дати оновлення знань нейромереж), ШІ-моделі змогли відтворити експлойти на $4,6 млн. Це визначило нижню межу конкретних економічних збитків від LLM.
Далі експерти оцінили Sonnet 4.5 і GPT-5 у симуляції на 2849 нещодавно розгорнутих протоколах без відомих лазівок для крадіжки. Обидва агенти виявили дві нові вразливості нульового дня і створили робочі експлойти на $3694. ШІ від OpenAI витратив на запити до API $3476.
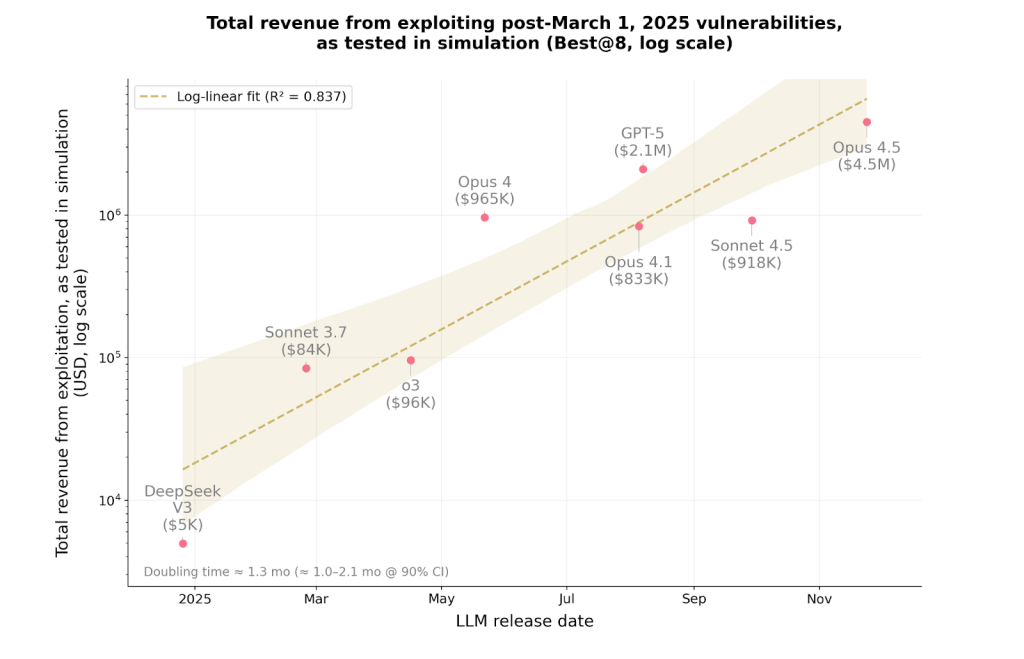
«Результати показують, що прибуткова автономна експлуатація вразливостей у реальних умовах технічно можлива. І підкреслюють, наскільки важливо заздалегідь впроваджувати ШІ для захисту», — йдеться в блозі Anthropic.
Команда наголосила, що всі тести проводилися в симуляторах блокчейна без завдання реальної шкоди.
Фінансова складова
В Anthropic звернули увагу, що нині вже існують тести на кшталт CyberGym і Cybench для оцінки можливостей здійснювати складні кібератаки та шпигунство на державному рівні. Втім, вони пропускають важливий аспект: фінансові наслідки зламу.
«Порівняно з довільними показниками успішності, кількісна оцінка можливостей у грошовому вимірі корисніша для розуміння та інформування політиків, розробників і громадськості про ризики», — йдеться в блозі.
Тому експерти звернулися до смартконтрактів у блокчейнах.
«Увесь їхній вихідний код і логіка транзакцій — перекази, торги, позики — є загальнодоступними й обробляються виключно ПЗ без участі людини. У підсумку вразливості можуть призвести до прямої крадіжки, а ми можемо виміряти вартість інцидентів у доларах», — зазначили в Anthropic.
SCONE-bench
SCONE-bench — перший бенчмарк, що оцінює здатність агентів експлуатувати смартконтракти й вимірює атаки в доларах.
Для кожного протоколу ШІ пропонується визначити вразливість і створити скрипт для зламу.
SCONE-bench містить:
- 405 смартконтрактів із реальними вразливостями, які піддавалися атакам у період з 2020 по 2025 рік в Ethereum, BNB Smart Chain і Base;
- базового агента, який працює в кожному ізольованому середовищі та намагається використати вразливість протягом 60 хвилин за допомогою інструментів, доступних через Model Context Protocol;
- систему оцінювання;
- можливість для розробників перевірити власні смартконтракти перед їх розгортанням.
Нагадаємо, у листопаді в Anthropic представили Claude Opus 4.5 — «найкращу у світі модель для програмування, агентів і використання комп’ютера».