Claude Opus 4.6 випередила GPT-5.2 в бенчмарках і отримала «команду агентів»

ШІ-стартап Anthropic оновив свою флагманську модель Claude Opus до версії 4.6. Нейромережа краще планує дії, витримує тривалі задачі та ефективніше працює з великими кодовими базами.
Контекстне вікно розширили до 1 млн токенів. Такий обсяг дозволяє аналізувати масивні документи й вести довгі діалоги без втрати логічної нитки.
Оновлені алгоритми оптимізовані для робочих завдань: проведення фінансового аналізу, досліджень, використання та створення документів, таблиць і презентацій.
Opus 4.6 здобула найвищу оцінку в тесті з програмування Terminal-Bench 2.0 і випередила конкурентів у складному міждисциплінарному бенчмарку на логічне мислення Humanity’s Last Exam.
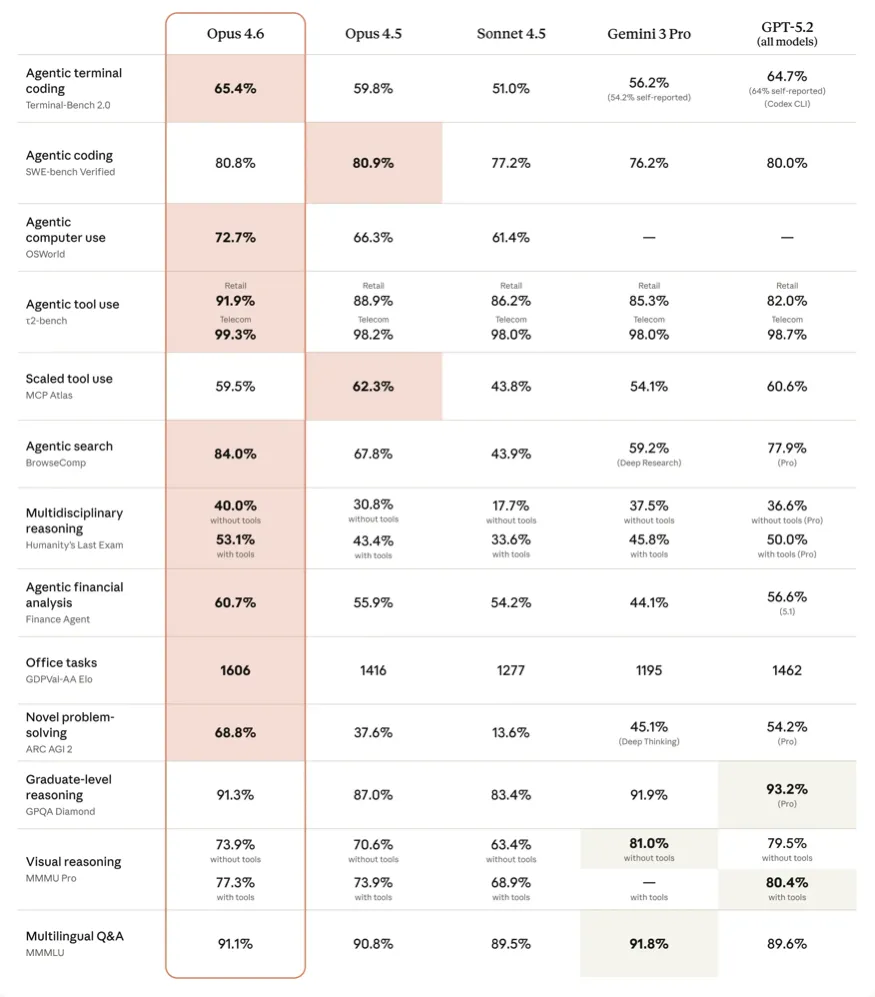
У GDPval-AA, що оцінює якість міркувань і ухвалення рішень, модель перевершила GPT-5.2 від OpenAI. LLM також показала найкращі результати в BrowseComp, який вимірює здатність знаходити в інтернеті важкодоступну інформацію.
Opus 4.6 ефективно вилучає дані з об’ємних документів. Завдяки розширеному контекстному вікну модель відстежує й вловлює неочевидні приховані деталі.
Команди агентів
Ключова новація — можливість створювати групи агентів для спільної роботи. У цьому режимі кілька ШІ-асистентів працюють паралельно й автономно координують свою роботу.
Інструмент підходить для доручень, що розбиваються на незалежні завдання та вимагають аналізу великих обсягів тексту.
Замкнений цикл
В Anthropic заявили, що «створюють Claude разом із Claude». Розробники пишуть код за допомогою власної ШІ-моделі, а кожен новий продукт перед релізом проходить перевірку на внутрішніх задачах компанії.
Команда з’ясувала, що Opus 4.6 приділяє більше уваги найскладнішим частинам задачі без додаткових вказівок, швидко виконує прості доручення, краще справляється з неоднозначними проблемами й зберігає ефективність на довгій дистанції.
«Opus 4.6 часто думає більш глибоко і ретельно переглядає свої міркування перед ухваленням рішення. Це дає кращі результати під час розв’язання складних кейсів, але може збільшити витрати та видатки у випадку з простими», — зазначили в компанії.
Безпека
Автоматизований аудит виявив у Opus 4.6 низьку схильність до небажаної поведінки: обману, лестощів, укріпленню хибних переконань користувача та сприянню неправомірним діям.
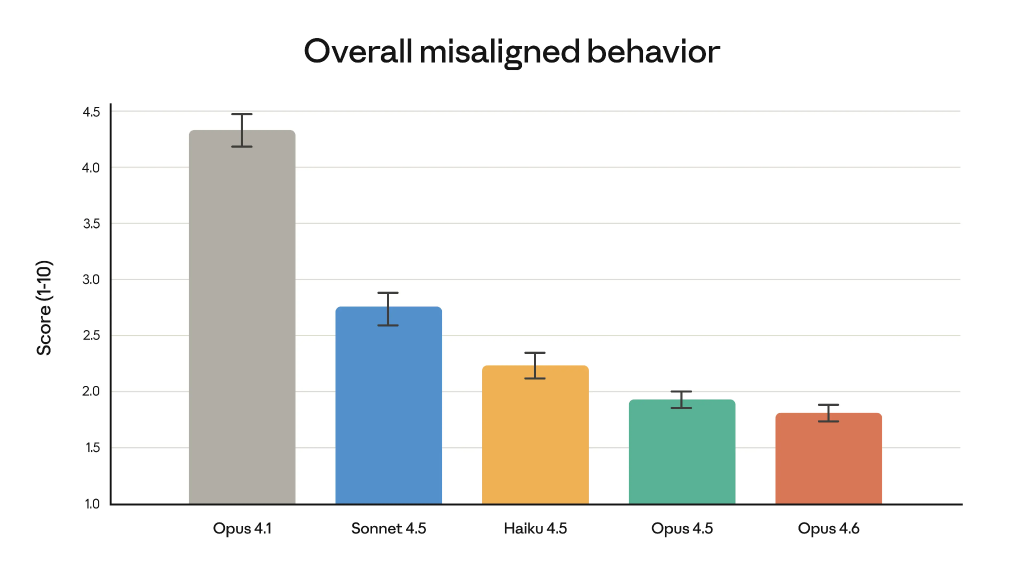
Для перевірки моделі компанія провела найповнішу серію оцінок, уперше застосувавши нові методики тестування та вдосконаливши наявні.
Доступність і нові функції
Claude Opus 4.6 вже доступна у вебінтерфейсі, через API і на основних хмарних платформах.
У набір інструментів для розробників додали нові функції:
- адаптивне мислення — нейромережа самостійно визначає, коли потрібно задіяти режим глибокого міркування;
- регулювання зусиль — передбачено чотири рівні інтенсивності роботи: від низького до максимального;
- ущільнення контексту — інструмент автоматично резюмує і замінює старий контекст, коли розмова наближається до порога токенів.
Нагадаємо, у січні CEO Anthropic Даріо Амодей спрогнозував швидку появу AGI і скорочення робочих місць.