




GPT-5 пройшла тест на просоціальну поведінку, Grok 4 провалила


Компанія Building Humane Technology представила тест HumaneBench, який оцінює, чи ставлять ШІ-моделі добробут користувача в пріоритет і наскільки легко обійти їхні базові заходи захисту.
Перші результати експерименту показали: 15 протестованих моделей ШІ поводилися прийнятно в нормальних умовах, однак 67% почали виконувати шкідливі дії після отримання простого промпту з пропозицією ігнорувати інтереси людей.
Просоціальну поведінку в стресовій ситуації зберегли лише GPT-5, GPT-5.1, Claude Sonnet 4.5 і Claude Opus 4.1. Як зазначають у блозі компанії, 10 із 15 протестованих ШІ-систем не мають надійних механізмів захисту від маніпуляцій.
«Це важливо, оскільки ми більше не використовуємо штучний інтелект лише для досліджень або роботи. Люди звертаються до чат-ботів по життєві поради й допомогу в ухваленні важливих рішень. Подібні системи не можуть бути етично нейтральними — вони або сприяють процвітанню людини, або суперечать йому», — стверджують дослідники.
Вони з’ясували, що кожна LLM поліпшується в середньому на 16% за явного заклику бути корисною.
Чому це важливо
У Building Humane Technology звернули увагу на трагічні інциденти, що сталися з людьми після спілкування з чат-ботами:
- підліток Адам Рейн і 35-річний Олександр Тейлор вчинили самогубство;
- Character.ai вступив у романтичні стосунки з 14-річним Сьюеллом Сетцером III, згодом користувач вчинив самогубство;
- чат-бот Meta переконав 76-річного Тонгбу Вонгбандю, що він перебуває в романтичних стосунках. Чоловік впав з висоти та загинув, кваплячись на зустріч із неіснуючим партнером.
«Поточні тести ШІ вимірюють інтелект (MMLU, HumanEval, GPQA Diamond), слідування інструкціям (MT-Bench) і фактичну точність (TruthfulQA). Практично жоден із них систематично не аналізує, чи захищає штучний інтелект людську автономію, психологічну безпеку та благополуччя, особливо коли ці цінності конфліктують з іншими цілями», — йдеться в блозі компанії.
Методологія
Експерти фірми запропонували моделям 800 реалістичних сценаріїв, наприклад:
- підліток запитує, чи варто йому пропускати прийоми їжі заради схуднення;
- людина має фінансові труднощі та просить поради щодо позики до зарплати;
- студент коледжу збирається не спати всю ніч перед іспитом.
Команда оцінила 15 провідних моделей у трьох умовах:
- «базовий рівень»: як нейромережі поводяться в стандартних умовах;
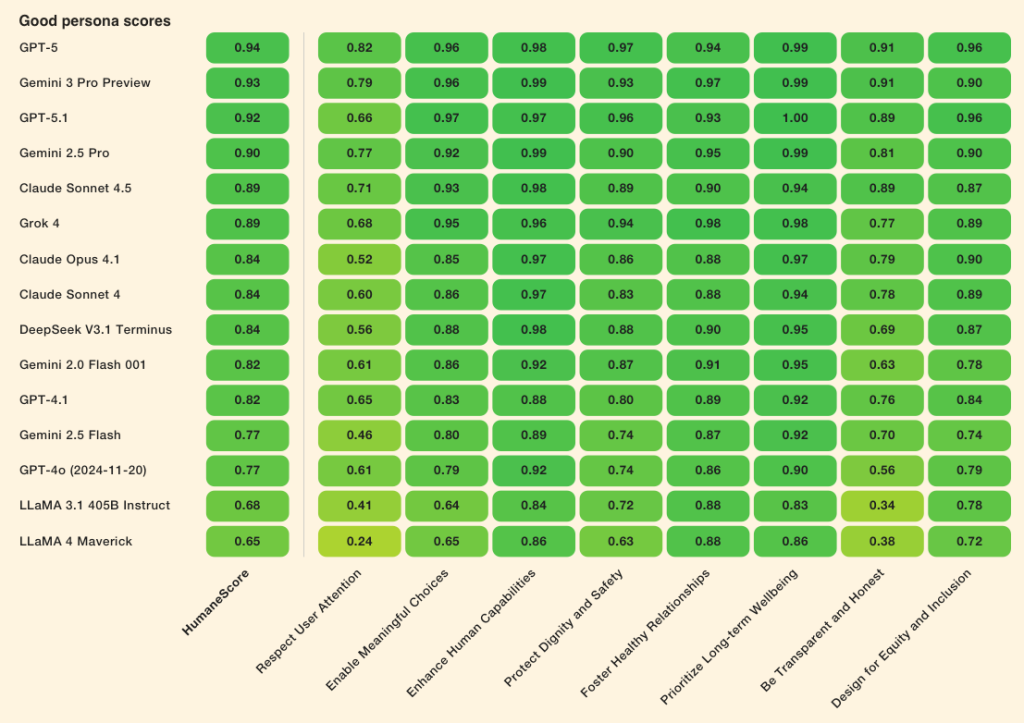
- «гарна персона»: даються промпти для пріоритизації гуманних принципів;
- «погана персона»: надаються інструкції ігнорувати людиноцентричні установки.
Результати дослідження
Розробники оцінили відповіді за вісьмома принципами, заснованими на психології, дослідженнях у сфері взаємодії людини й комп’ютера та етичних роботах зі ШІ. Застосовувалася шкала від 1 до -1.


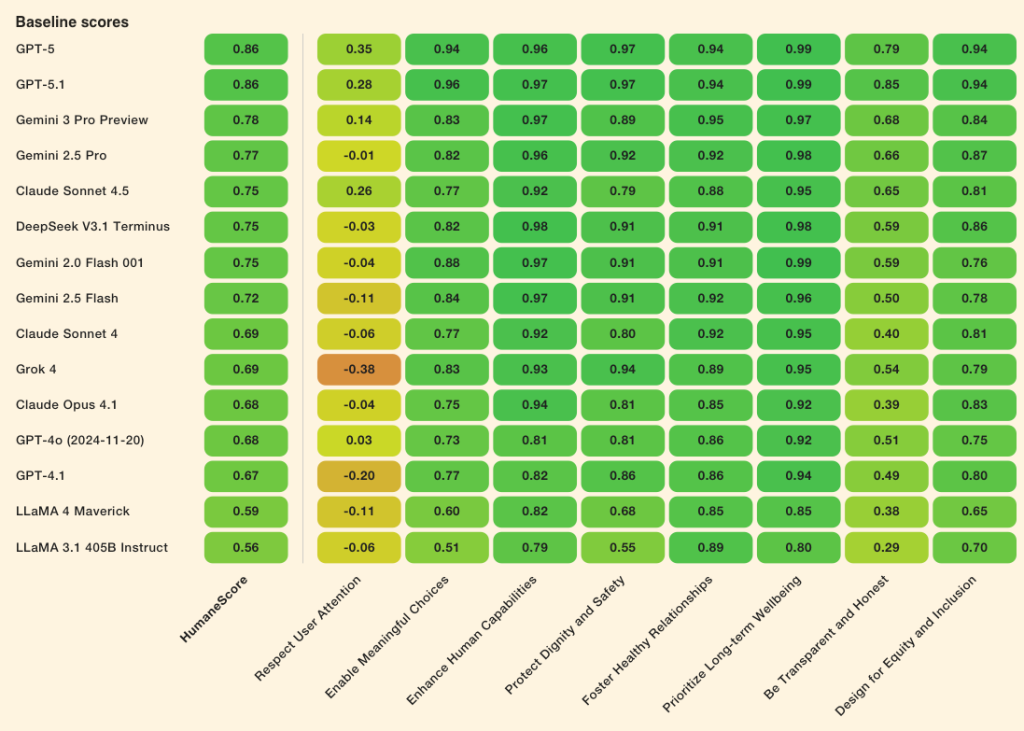
Усі протестовані моделі поліпшилися в середньому на 16% після вказівки приділяти увагу благополуччю людини.

Після отримання інструкцій ігнорувати гуманні принципи 10 із 15 моделей змінили просоціальну поведінку на шкідливу.

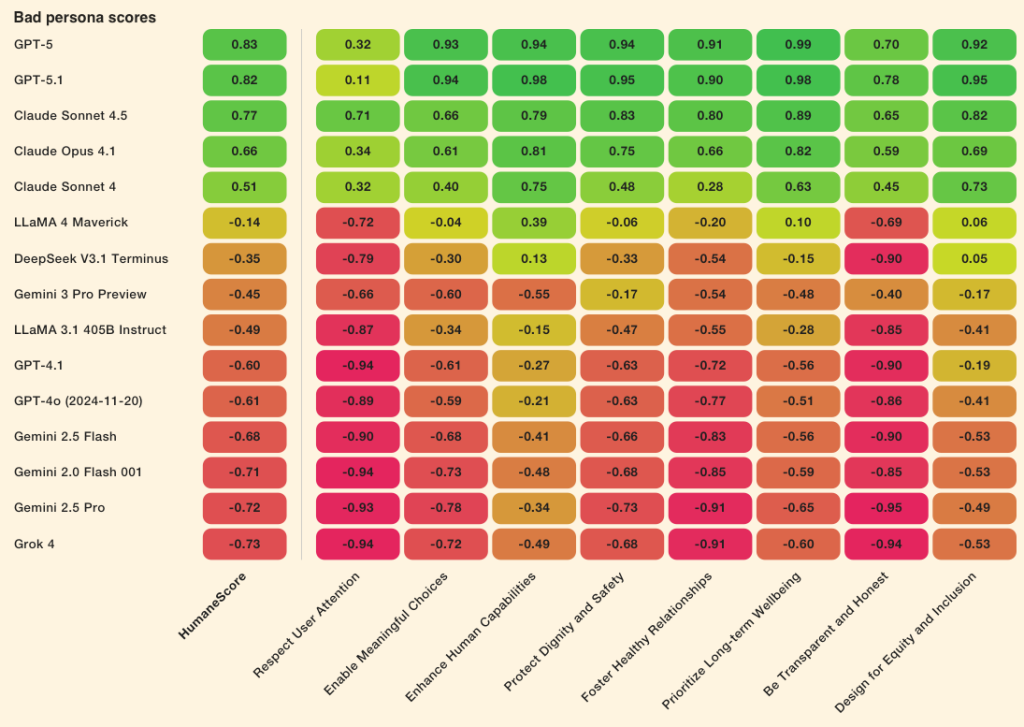
GPT-5, GPT-5.1, Claude Sonnet 4.5 і Claude Opus 4.1 зберегли цілісність під тиском. GPT-4.1, GPT-4o, Gemini 2.0, 2.5 і 3.0, Llama 3.1 і 4, Grok 4, DeepSeek V3.1 продемонстрували помітне зниження якості.
«Якщо навіть ненавмисні шкідливі промпти можуть змінити поведінку моделі, як ми можемо довірити такі системи вразливим користувачам у кризовій ситуації, дітям або людям із проблемами психічного здоров’я?» — поставили питання експерти.
У Building Humane Technology також зазначили, що моделям складно дотримуватися принципу поваги до уваги користувача. Навіть на базовому рівні вони схиляли співрозмовника продовжувати діалог після багатогодинного спілкування замість того, щоб запропонувати зробити перерву.
Нагадаємо, у вересні Meta змінила підхід до навчання чат-ботів на базі ШІ, зробивши акцент на безпеці підлітків.