Конкурент Sora навчився генерувати відео зі складним монтажем

Китайський розробник Kuaishou представив третю версію моделі для генерації відео Kling AI.
🚀 Introducing the Kling 3.0 Model: Everyone a Director. It’s Time.
An all-in-one creative engine that enables truly native multimodal creation.
— Superb Consistency: Your characters and elements, always locked in.
— Flexible Video Production: Create 15s clips with precise… pic.twitter.com/CJBILOdMZs— Kling AI (@Kling_ai) February 4, 2026
«Kling 3.0 працює на основі глибоко уніфікованої навчальної платформи, забезпечуючи по-справжньому нативний мультимодальний ввід і вивід. Завдяки безшовній інтеграції аудіо та просунутому контролю узгодженості елементів модель наповнює згенеровану частину сильнішим відчуттям життя та цілісності», — йдеться в анонсі.
Модель об’єднує кілька задач: перетворення тексту, зображень і референсів у відео, додавання або видалення контенту, модифікація і трансформація роликів.
Тривалість роликів зросла до 15 секунд. Серед інших покращень — гнучкіше керування кадрами та точніше дотримання промптів. Підвищено загальний реалізм: рухи персонажів стали виразнішими та динамічнішими.
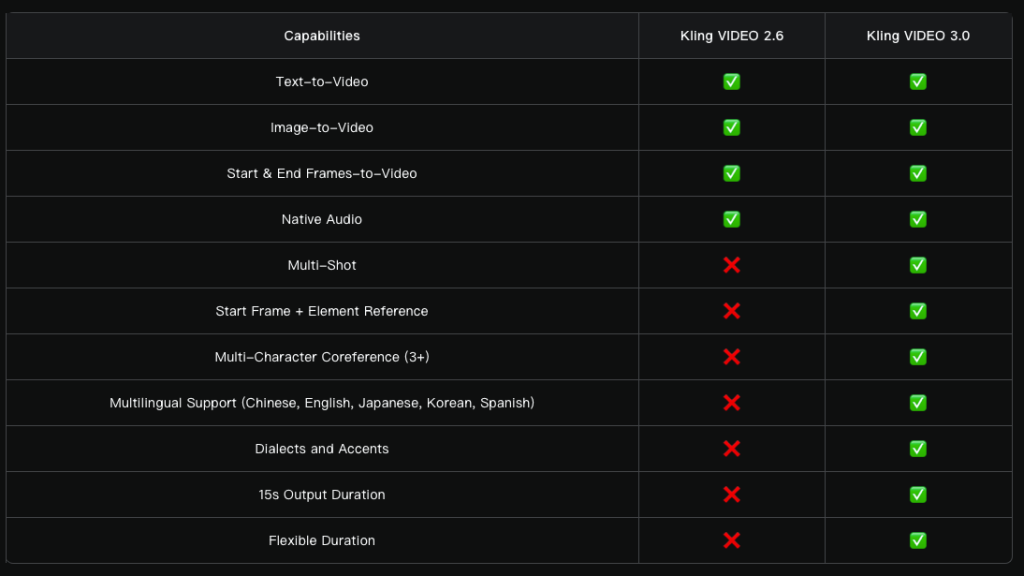
Нова функція Multi‑Shot аналізує промпт, визначаючи структуру сцени та типи кадрів. Інструмент автоматично налаштовує ракурси камери й композицію.
Модель підтримує різні монтажні рішення: від класичних діалогів за схемою «кадр‑контркадр» до паралельного наративу й сцен із закадровим голосом.
«Більше не потрібно втомливо різати й монтувати відео — однієї генерації достатньо, щоб отримати кінематографічний ролик і зробити складні аудіовізуальні форми доступними для всіх творців», — йдеться в анонсі.
Kling 3.0 is truly “one giant leap for AI video generation”! Check out this amazing mockumentary from Kling AI Creative Partner Simon Meyer! pic.twitter.com/Iyw919s6OJ
— Kling AI (@Kling_ai) February 5, 2026
Окрім стандартної генерації відео за зображенням, Kling 3.0 підтримує одразу кілька картинок як референси, а також відео‑джерела в ролі елементів сцени.
Модель фіксує характеристики персонажів, предметів і епізоду. Незалежно від руху камери та розвитку сюжету ключові об’єкти залишаються стабільними й узгодженими впродовж усього відео.
Розробники вдосконалили нативне аудіо: система точніше синхронізує мовлення з мімікою, а в сценах із діалогами дозволяє вручну вказувати конкретного спікера.
Розширено перелік підтримуваних мов: китайська, англійська, японська, корейська та іспанська. Також покращено передачу діалектів і акцентів.
Крім того, команда оновила мультимодальну модель O1 до Video 3.0 Omni.

Є можливість завантажити аудіо з мовленням від трьох секунд і виділити голос або записати відео з персонажем тривалістю від трьох до восьми секунд для отримання його основних характеристик.
Конкуренти Sora наступають
OpenAI представила модель відеогенерації Sora в лютому 2024 року. Інструмент викликав захват у соцмережах, однак публічний реліз відбувся лише в грудні.
Майже за рік користувачам відкрили доступ до генерації відео за текстовими описами, «оживлення» зображень і доповнення готових роликів.
iOS‑застосунок Sora вийшов у вересні та відразу привернув увагу аудиторії: у перший день його встановили понад 100 000 разів. Сервіс подолав позначку в 1 млн завантажень швидше за ChatGPT, попри доступ за запрошеннями.
Втім невдовзі тренд розвернувся. У грудні кількість завантажень скоротилася на 32% відносно попереднього місяця. У січні низхідна динаміка збереглася — застосунок завантажили 1,2 млн разів.
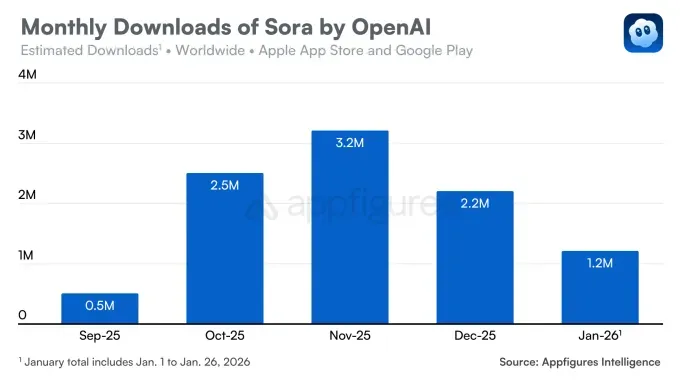
Спад зумовлений низкою факторів. По‑перше, конкуренцію посилила модель Nano Banana від Google, яка зміцнила позиції Gemini.
Sora також змагається з Meta AI та її функцією Vibes. У грудні тиск на ринок посилив стартап Runway, чия модель Gen 4.5 перевершила аналоги в незалежних тестах.
По‑друге, продукт OpenAI зіткнувся з проблемою порушення авторських прав. Користувачі створювали відео з популярними персонажами на кшталт «Губки Боба» чи «Пікачу», через що компанії довелося посилити обмеження.
У грудні ситуація стабілізувалася після укладання угоди з Disney, яка дозволила юзерам генерувати відео з персонажами студії. Втім це не призвело до зростання завантажень.
Нагадаємо, у жовтні дипфейки із Семом Альтманом заполонили Sora.