




OpenAI випустила GPT‑5.4 із комп’ютерним зором


Компанія OpenAI випустила GPT‑5.4 і GPT‑5.4 Pro за два дні після релізу версії 5.3 Instant.
GPT-5.4 Thinking and GPT-5.4 Pro are rolling out now in ChatGPT.
GPT-5.4 is also now available in the API and Codex.
GPT-5.4 brings our advances in reasoning, coding, and agentic workflows into one frontier model. pic.twitter.com/1hy6xXLAmJ
— OpenAI (@OpenAI) March 5, 2026
Стандартна версія GPT‑5.4 доступна у веб‑інтерфейсі ChatGPT, через API і в інструменті Codex. Версію GPT‑5.4 Thinking відкрили для передплатників Plus, Team і Pro.
Для користувачів тарифу Pro і корпоративних клієнтів Enterprise призначена GPT‑5.4 Pro, яка також доступна через API.
Базова вартість використання становить $2,5 за 1 млн вхідних токенів і $15 за 1 млн вихідних. Тарифи для версії Pro суттєво вищі: $30 і $180 за 1 млн токенів відповідно.
Продуктивність у робочих завданнях
GPT‑5.4 видає стабільніші й якісніші результати в реальних сценаріях застосування. У бенчмарку GDPval, що оцінює виконання завдань за 44 професіями, версія досягла показника 83%. Це означає, що модель працює на рівні профільних фахівців або перевершує їх. Для порівняння, результат GPT‑5.2 становив 70,9%.


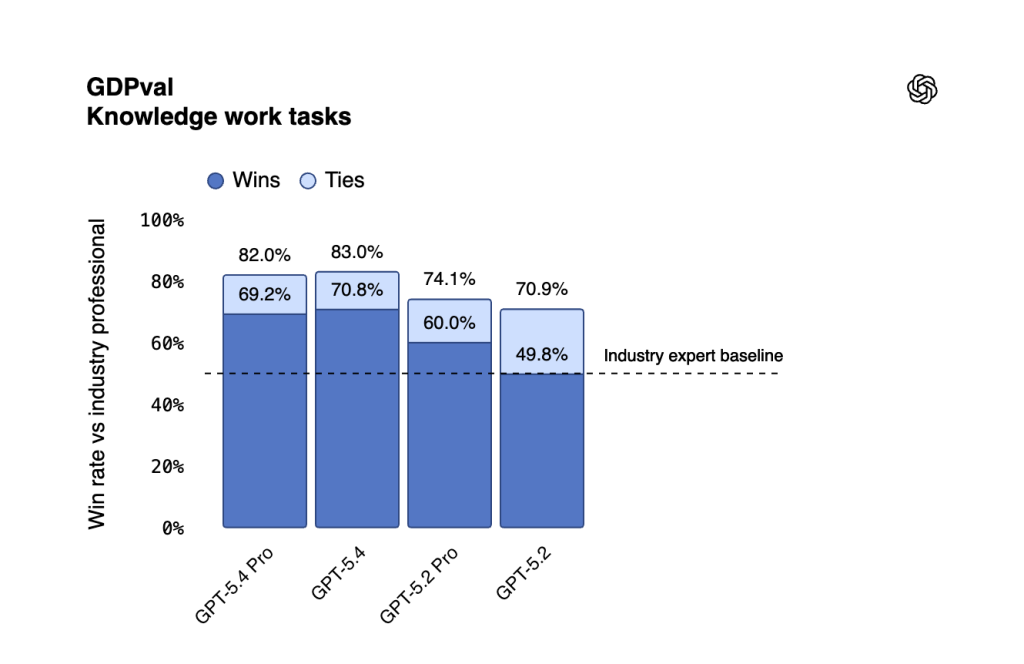
Особливу увагу розробники приділили роботі з таблицями, презентаціями та документами. У завданнях рівня молодшого аналітика інвестбанку GPT‑5.4 набрала 87,3% проти 68,4% у GPT‑5.2.
Презентації від нової моделі оцінювачі віддавали перевагу у 68% випадків — за кращу естетику, різноманіття та ефективне використання генерації зображень.

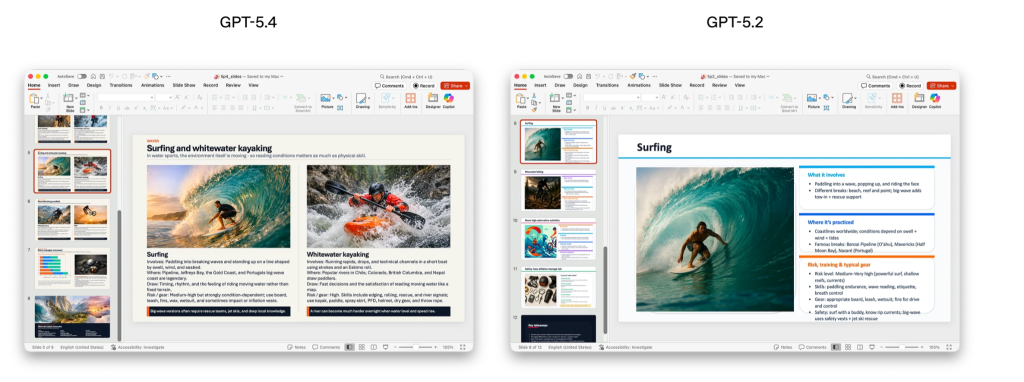
GPT‑5.4 також стала найточнішою моделлю OpenAI з погляду роботи з фактами. Під час тестування на промптах із заздалегідь відомими помилками:
- окремі твердження виявлялися хибними на 33% рідше;
- повні відповіді містили помилки на 18% рідше порівняно з GPT‑5.2.
Комп’ютерний зір
Версія вперше отримала вбудовані можливості комп’ютерного зору та керування ПК. Модель здатна використовувати мишу і клавіатуру, орієнтуючись на скриншоти, а також писати код для автоматизації через Playwright.
Поведінку налаштовують під конкретні сценарії з урахуванням допустимого рівня ризику.
У бенчмарку OSWorld‑Verified (керування робочим столом) GPT‑5.4 успішно виконала 75% завдань, обійшовши попередню версію (47,3%) і людину (72,4%). Прогрес пов’язаний із поліпшеним візуальним сприйняттям:
- у тесті MMMU‑Pro (розуміння і логіка) результат становив 81,2% проти 79,5% у GPT‑5.2;
- в OmniDocBench (аналіз документів) середній показник помилок знизився з 0,140 до 0,109.
Програмування
У кодингу модель зрівнялася зі спеціалізованою GPT‑5.3‑Codex, але працює швидше.
У Codex з’явився режим /fast, що прискорює генерацію у півтора раза без втрати якості. За результатами внутрішніх тестів GPT‑5.4 показала високі результати у складних завданнях фронтенд‑розробки.
Також представлено експериментальну навичку Playwright (Interactive). Вона дозволяє моделі візуально налагоджувати веб‑ та Electron‑застосунки, тестуючи власний код прямо в процесі написання.
Інструменти
У GPT‑5.4 з’явилася функція пошуку інструментів (Tool Search). Раніше системі доводилося заздалегідь завантажувати в контекст описи всіх доступних плагінів. Це додавало тисячі зайвих токенів до кожного запиту і збільшувало вартість.
Тепер модель отримує лише базовий список і за потреби самостійно знаходить і підвантажує потрібні параметри. У тестах на базі MCP Atlas такий підхід знизив споживання токенів на 47% без втрати точності.
Вебпошук також став продуктивнішим: у бенчмарку BrowseComp показники зросли на 17%, а версія Pro досягла рекордних 89,3%. GPT‑5.4 Thinking ефективніше збирає інформацію з багатьох джерел, краще опрацьовує складні запити й видає більш структуровані відповіді.
Керованість і контекст
Під час роботи зі складними запитами GPT‑5.4 Thinking у ChatGPT спершу демонструє користувачу план дій. Це дозволяє на ходу скоригувати напрям без перезапуску генерації та зайвих уточнень. Функція вже доступна на сайті й в Android‑застосунку, скоро з’явиться на iOS.
Модель також краще утримує контекст у довгих діалогах і довше обмірковує складні завдання. Це допомагає зберігати зв’язність і релевантність відповідей навіть під час роботи з великими масивами інформації.
Нагадаємо, на початку березня користувачі бойкотували ChatGPT на тлі угоди OpenAI з Пентагоном.