




Стенфорд: 35% нових вебсайтів створені ШІ


Станом на середину 2025 року близько 35% нових вебсайтів були створені повністю або частково за допомогою штучного інтелекту. Такого висновку дійшли дослідники Стенфордського університету.
До публічного запуску ChatGPT від OpenAI у листопаді 2022 року показник був майже нульовим. За кілька років частка ШІ-контенту зросла до понад третини нових публікацій в інтернеті.


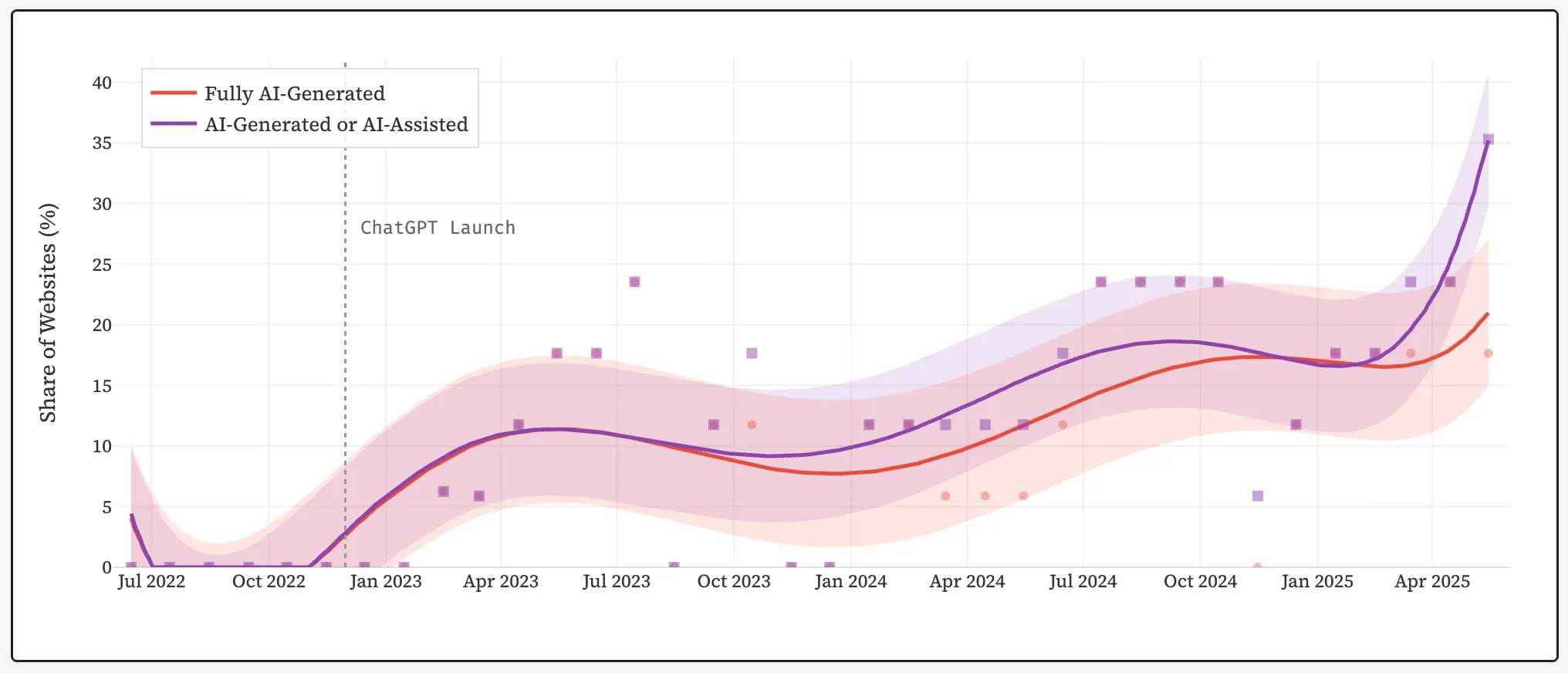
Дослідники проаналізували 33 місяці архівних копій сайтів із Wayback Machine за допомогою детектора Pangram v3. Мета — з’ясувати, як зростання ШІ-текстів перебудовує структуру всесвітньої павутини.
Ключові зміни
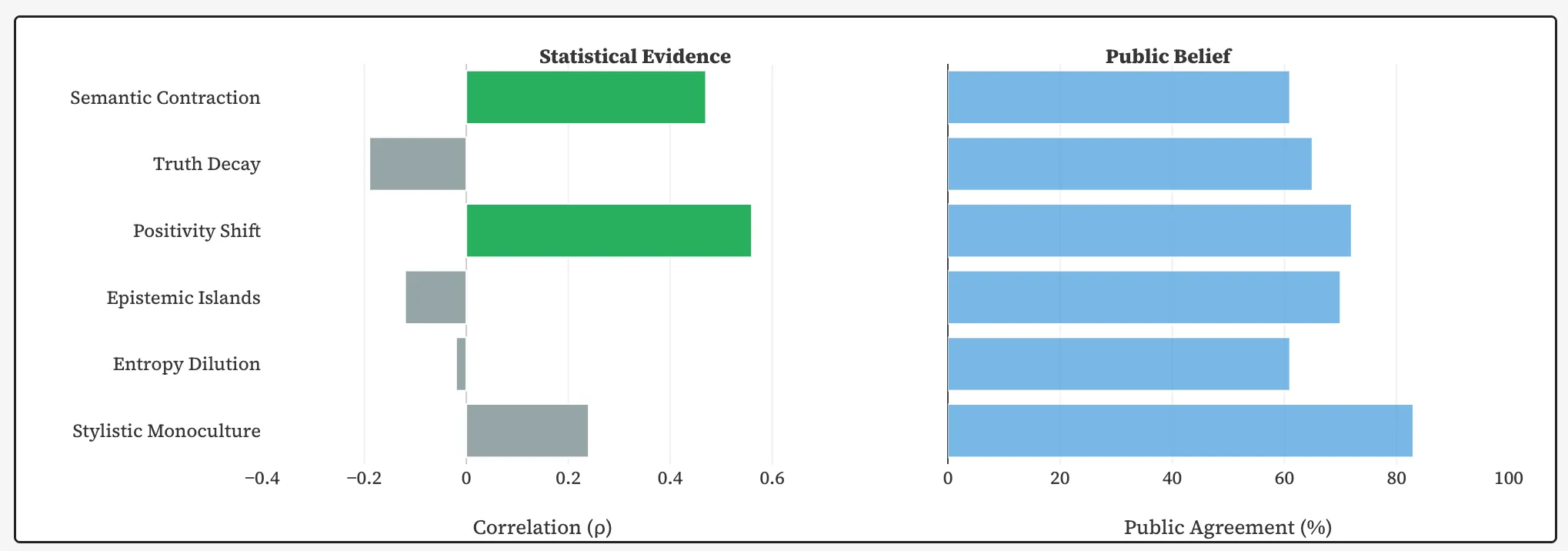
Зафіксовано зниження семантичного різноманіття. Сторінки, згенеровані нейромережами, на 33% більш схожі між собою, ніж тексти, написані людьми. Різні сайти дедалі частіше переказують ті самі ідеї майже ідентичними фразами.
На думку авторів, справа не лише у масовому копірайтингу за допомогою ШІ. Проблема глибша: поступово звужується розмаїття формулювань і ідей. Великі мовні моделі (LLM) за своєю природою обирають най«усередненіші» відповіді та відтворюють шаблонний дискурс.
Змінився й емоційний тон публікацій. Контент, згенерований ШІ, виявився на 107% більш позитивним за людський. У Стенфорді пов’язали це з уже задокументованою схильністю LLM до підлабузництва.
У процесі навчання розробники оптимізують нейромережі на приємні, безпечні та соціально схвалювані відповіді. У підсумку значна частина нових сайтів формує «стерильно дружнє» інформаційне середовище. У ньому менше різких оцінок і конфліктів, але й менше живої людської полеміки.
Що не підтвердилося
Кілька популярних побоювань не знайшли статистичного підтвердження. Дослідники не виявили суттєвої кореляції між зростанням частки ШІ-контенту та падінням фактичної точності, збільшенням кількості явних помилок чи повним стилістичним вирівнюванням текстів до єдиного шаблону.

Науковці окремо вказали на ефект, який досі обговорювався переважно теоретично, — модельний колапс (model collapse).
Якщо нові нейромережі навчати на даних з великою часткою ШІ-контенту, система починає споживати власні усереднені відповіді. Це зменшує варіативність, погіршує якість і загрожує тим, що надалі LLM вчитимуться не у людей, а в «синтетичного відлуння» попередниць.
Експерти разом з Internet Archive планують перетворити дослідження на систему постійного моніторингу частки ШІ-контенту в інтернеті.
Нагадаємо, у квітні Сем Альтман назвав п’ять принципів OpenAI для досягнення «загального ШІ-блага».