





«Я здаюся». Нейромережі не впоралися з недільними загадками


Група дослідників використовувала щотижневу рубрику з головоломками ведучого NPR Вілла Шортца для перевірки навичок «міркування» у моделей штучного інтелекту.
Експерти з кількох американських коледжів та університетів за підтримки стартапу Cursor створили універсальний тест для ШІ-моделей, використовуючи загадки з епізодів Sunday Puzzle. За словами команди, дослідження виявило цікаві деталі, включно з тим фактом, що чат-боти іноді «здаються» й усвідомлено дають неправильні відповіді.
Sunday Puzzle — щотижнева радіовікторина, в якій слухачам ставлять запитання на логіку і синтаксис. Для розв’язання не потрібно мати особливих теоретичних знань, але потрібні критичне мислення і навички міркування.
Один зі співавторів дослідження Арджун Гуха пояснив TechCrunch перевагу методу «загадок» тим, що він не перевіряє наявність езотеричних знань, а формулювання завдань ускладнюють використання «механічної пам’яті» ШІ-моделей.
«Ці пазли важкі, оскільки дуже складно домогтися осмисленого прогресу, доки ви її не розв’яжете — ось коли відразу складається [остаточна відповідь]. Це вимагає поєднання інтуїції та процесу виключення», — пояснив він.
Однак Гуха наголосив на неідеальності методу — Sunday Puzzle орієнтований на англомовну аудиторію, а самі тести є загальнодоступними, тож ШІ здатен «шахраювати». Дослідники мають намір розширювати бенчмарк новими загадками, зараз він складається приблизно з 600 завдань.
У проведених тестах o1 і DeepSeek R1 значно перевершили інші моделі в здатності «міркувати». Провідні нейромережі ретельно перевіряли себе перед відповіддю, але процес займав у них набагато більше часу, ніж зазвичай.


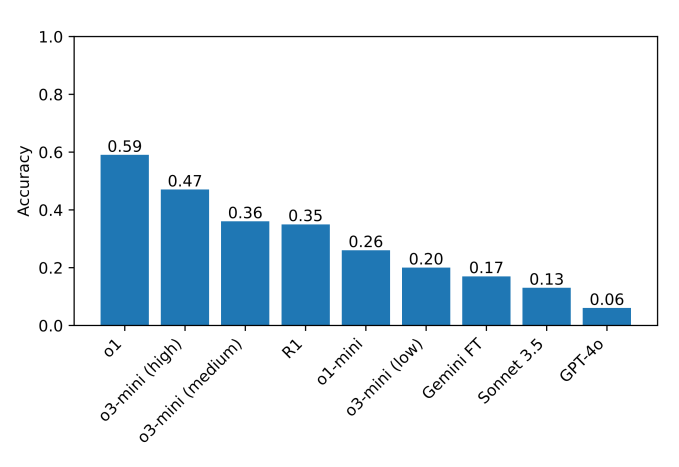
Однак точність ШІ не перевищує 60%. Деякі моделі зовсім відмовлялися вирішувати загадки. Коли нейромережа від DeepSeek не могла знайти правильну відповідь, то під час міркування писала: «Я здаюся», а потім видавала неправильну відповідь, ніби обрану навмання.
Інші моделі по кілька разів намагалися виправити попередні помилки, але все одно зазнавали невдачі. ШІ назавжди «застрявали в роздумах», генерували нісенітницю, а іноді давали правильні відповіді, проте потім відмовлялися від них.



«У складних завданнях R1 від DeepSeek буквально говорить, що він „розчарувався“. Кумедно спостерігати, як модель імітує те, що може сказати людина. Залишається з’ясувати, як „розчарованість“ у міркуваннях може вплинути на якість результатів моделі», — підкреслив Гуха.
Раніше дослідник перевірив сім популярних чат-ботів у шаховому турнірі. Жодна нейромережа не змогла повноцінно впоратися з грою.